Transformer 主包括两个部分,Encoder 和 Decoder,整体流程如下
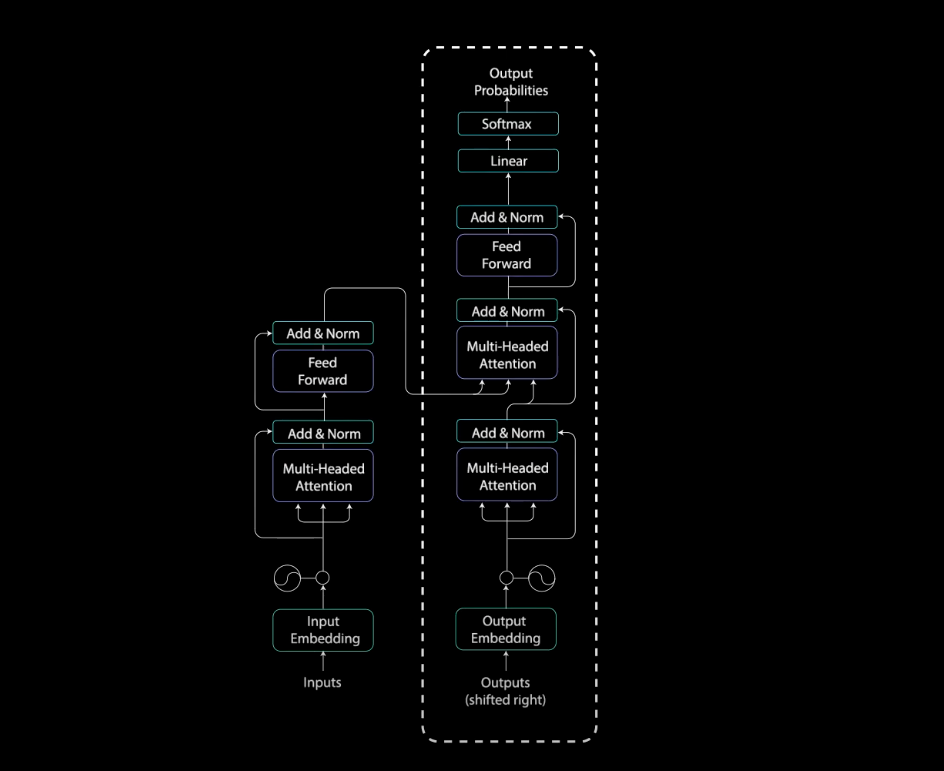
Encoder
Encoder 包含了两个子层,一个 multi-headed attention 子层,一个全连接子层。此外这两个子模块都是用了残差连接,然后从一个归一化层输出
\(Encoding(x,mask)=FeedForward(MultiHeadAttention(x))\)
多头注意力 Sublayer
\(Z=MultiHead(X)=Concat(head_0,...,head_h)W^O\)
\(head_i=Z_i=Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V; Q=XW^Q, K=XW^K, V=XW^V\)
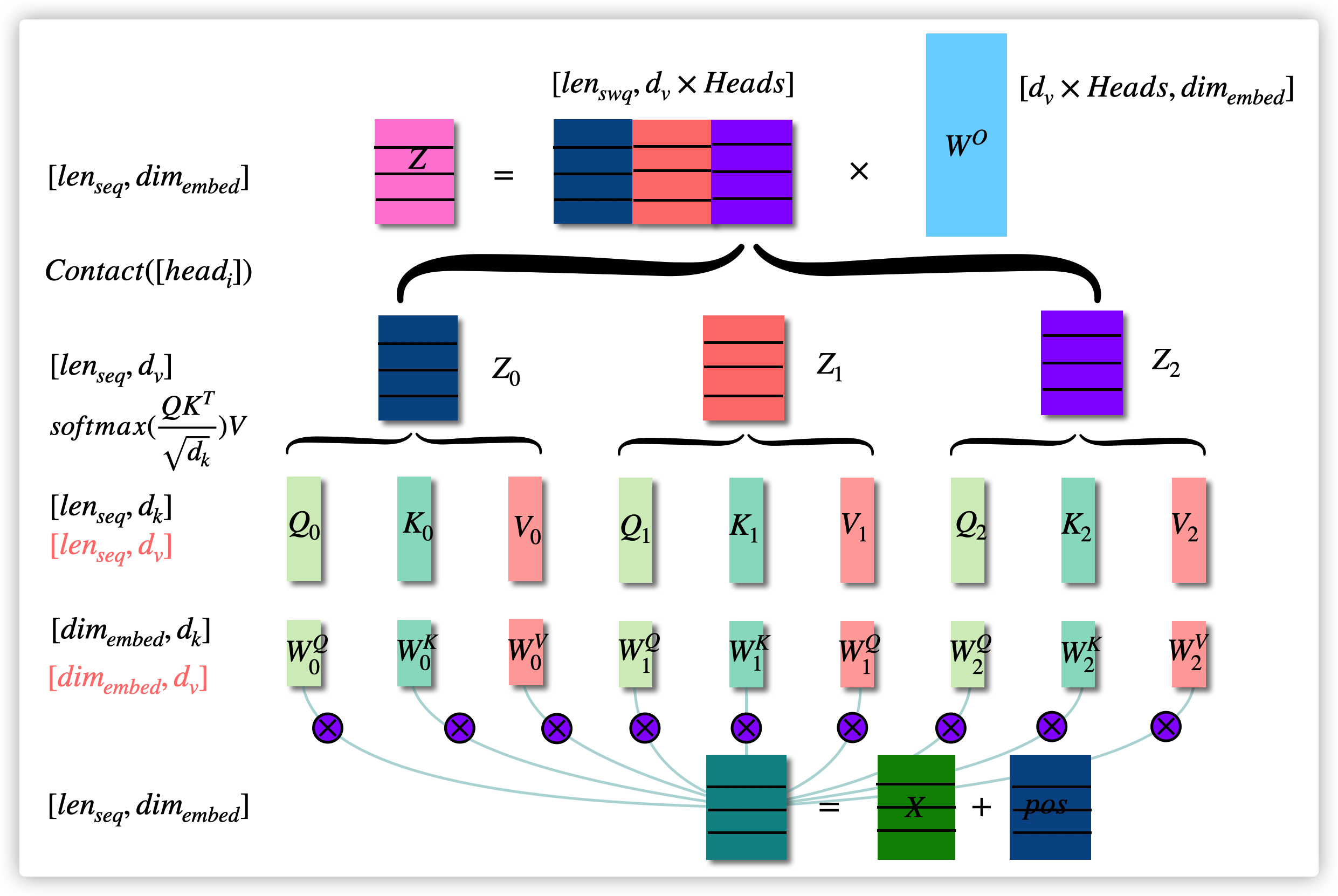
全连接层 Sublayer
从全连接层输出的向量维度跟输入的维度一致, \(FFN(x)=max(0, xW_1+b_1)W_2+b_2\)
Add&Norm
\(Z_n=LayerNorm(Z_{n-1}, SubLayer(Z_{n-1}))\)
Decoder
根据 Transformer 最后一层 Encoder 出来的向量,也就是 \(LayerNorm(Z_{n-1}+Z_{n})\),\(n\) 为 Encoder 的数量计算得到的 attention 向量 \(K\) 和 \(V\)。这两个矩阵将作为 Decoder 的输入来帮助 Decoder 关注输入序列中的重要位置信息
\(Decoding(x,memory,mask1,mask2)=FeedForward(MultiHeadAttention(MultiHeadAttention(x,mask1),memory,mask2))\)
第一个 multi-headed self attention 层
用于训练 Decoder 的输出序列按照时间步来进行,每个时间步输入当前位置的前面所有的序列信息,这可以通过在 self-attnetion 子模块中的 softmax 层前面用 \(-inf\) mask 掉当前位置之后的序列信息。这样 self attention 层输出的就是被 mask 后的输出序列的 \(Z\)  对于机器对话任务而言,Decoder 的工作模式如下图所示
对于机器对话任务而言,Decoder 的工作模式如下图所示
第二个 multi-headed encoder-decoder 层
对于这个 encoder-decoder 子模块而言,它使用了从 Encoder 的输出向量复制两份作为 \(Q\) 和 \(K\),使用了 Decoder self-attention 子模块的 \(V\) 作为输入,这个子模块为输出序列匹配了输入序列。读者肯定会有疑问,输入序列的长度(也就是 \(Q\) 和 \(K\) 矩阵的高度)和输出序列的长度(也就是 \(V\) 矩阵的高度)不一样,怎么能进行计算呢?答案是 Transformer 给输入和输入序列定长为 512,多余的没有内容的地方用一些空字符替代。
线性分类器和最后一个 softmax
最后一层分类器根据前面的输出序列信息和输入序列信息来预测对于当前位置的词汇,因此最后 softmax 的输出向量的维度为所有输出序列包含的词汇表的大小 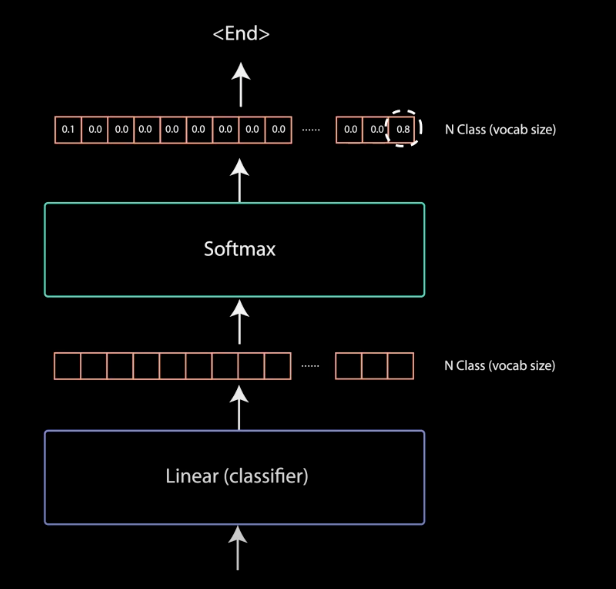
Loss Function
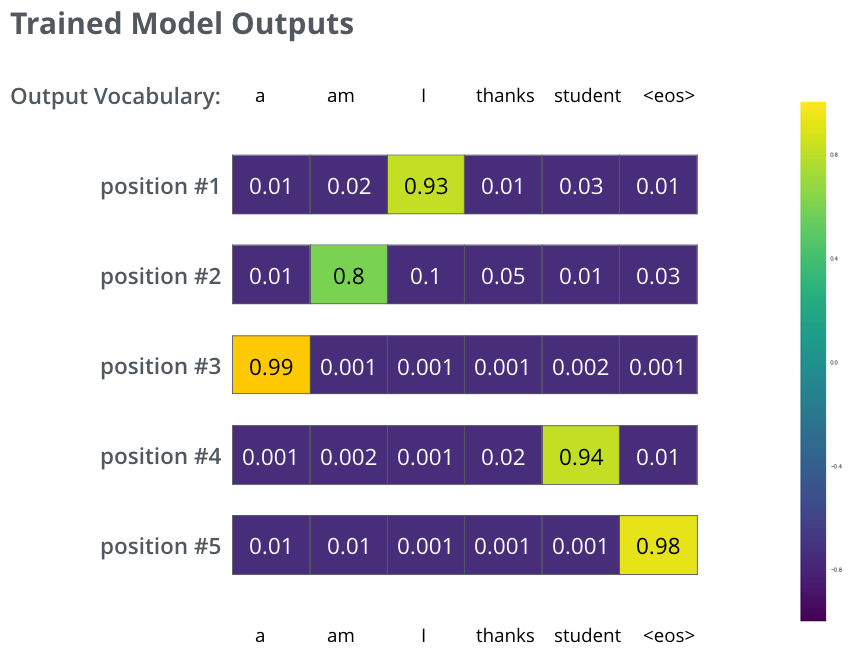
对于某个翻译的实例 ("Je suis etudiant, merci" --> "I am a student, thanks"),此时预测的词是 “I”,那么我们需要 softmax 层输出的是 \([0,0,1,0,0,0]\),通过softmax 层的输出向量和这个期望的向量进行交叉熵或者 KL 距离计算,来作为 Loss
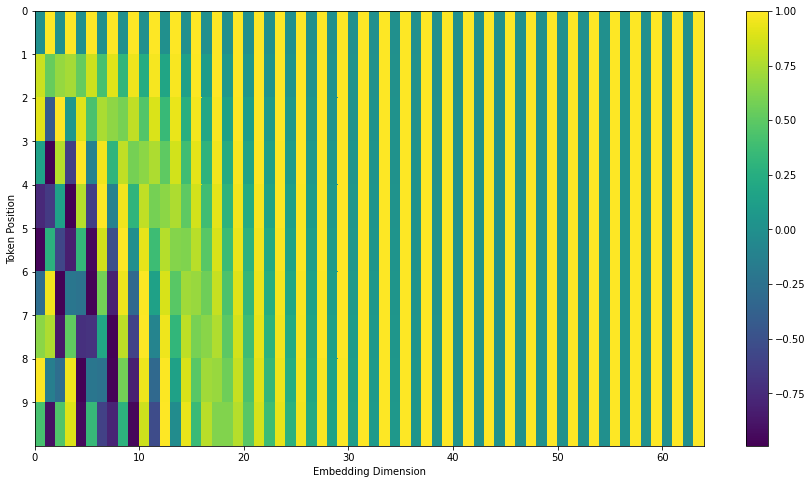
Position Encoding
为了向 Transformer 引入词汇的位置信息,通过下面的方法对位置进行编码来实现,最终得到下图的矩阵,形状为 \(len_{seq}\times dim_{embed}\)
对于句子中第 \(pos\) 个词汇的位置向量的偶数位,\(PE(pos,2i)=sin(\frac{pos}{10000^{2i/dim_{embed}}})\)
对于句子中第 \(pos\) 个词汇的位置向量的奇数位,\(PE(pos,2i+1)=cos(\frac{pos}{10000^{2i/dim_{embed}}})\)
参考 (References)
- Attention is All You Need
- Stanford implement of Transformer
- https://jalammar.github.io/illustrated-transformer/
- https://towardsdatascience.com/illustrated-guide-to-transformers-step-by-step-explanation-f74876522bc0
- https://wandb.ai/authors/One-Shot-3D-Photography/reports/-Transformer---Vmlldzo0MDIwMjc