使用了Mask Language Model(MLM) 和 Next Sentence Prediction(NSP) 的多任务训练目标;
输入向量
输入为每个 Token 位置上的 Token Embedding,Segment Embedding 和 Position Embedding 的和
Token Embedding: 就是单词的词向量表达(比如 Word2vec)。第一个单词是 CLS 标志,用于做句子分类任务;SEP 标志用于区分两个句子前后顺序(当输入有两个句子时)
Segment Embedding:用于区分两个句子,用于帮助做句子对的任务(如果只有一个句子则只需要 \(E_A\))
Position Embedding:用于编码单词的位置信息,跟 Transformer 一样 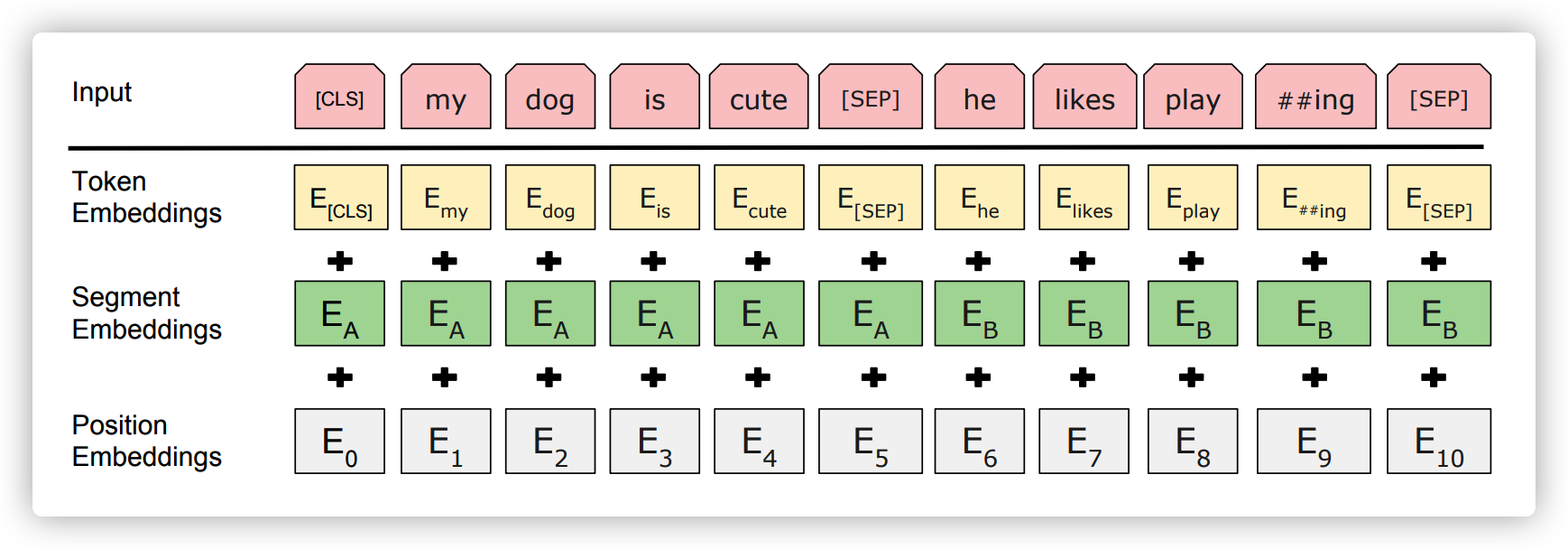
预训练任务
预训练 Next Sentence Prediction(NSP) 任务
这是一个二分类任务,用于判断 Sentence B 是不是 Sentence A 的下一句(IsNext 或者 NotNext)
对于语料库中的句子,50% 的句对(Sentence Pair)是前后句关系,50% 的 B 句是随机选择的
A 句加 B 句的总长度不超过 512
Mask 语言模型
根据上面构造的句对数据,再对句对中的 Token Embedding 进行随机掩盖,要求模型去预测被掩盖的单词。作者对数据集中的 15% 进行掩盖操作。于这 15% 的单词,分三个部分用不同方法来 Mask 1
2
380%:my dog is hairy -> my dog is [mask]
10%:my dog is hairy -> my dog is apple
10%:my dog is hairy -> my dog is hairy
特殊任务(Fine Tuning)
预训练的 Bert 已经学习到了较通用的知识,但是为了进一步提升在特殊任务上的表现,被训练过的 Bert 需要用特定任务的数据再进行一次训练,这次训练就叫做 FineTuning
多句子分类:CLS+句子A+SEP+句子B。利用CLS分类
单句子分类:CLS+句子。利用CLS进行分类
SQuAD:CLS+问题+SEP+文章。利用所有文章单词的输出做计算答案的 start 和 end 位置,用一个向量 \(S\)(设置一个模型内部参数)与句子 B 中每个位置的 Bert 最后一层输出 \(T_i\) 做內积,那么位置 \(j\) 为答案开始的概率为 \(P_{start}(j)=\frac{e^{S\cdot T_j}}{\sum_i S\cdot T_i}\);对于结束位置也可以设置一个向量 \(E\) 来做类似训练
NER:CLS+句子。利用句子单词做标记,然后用输出的词汇的 Tag 来进行 Fine-Tuning
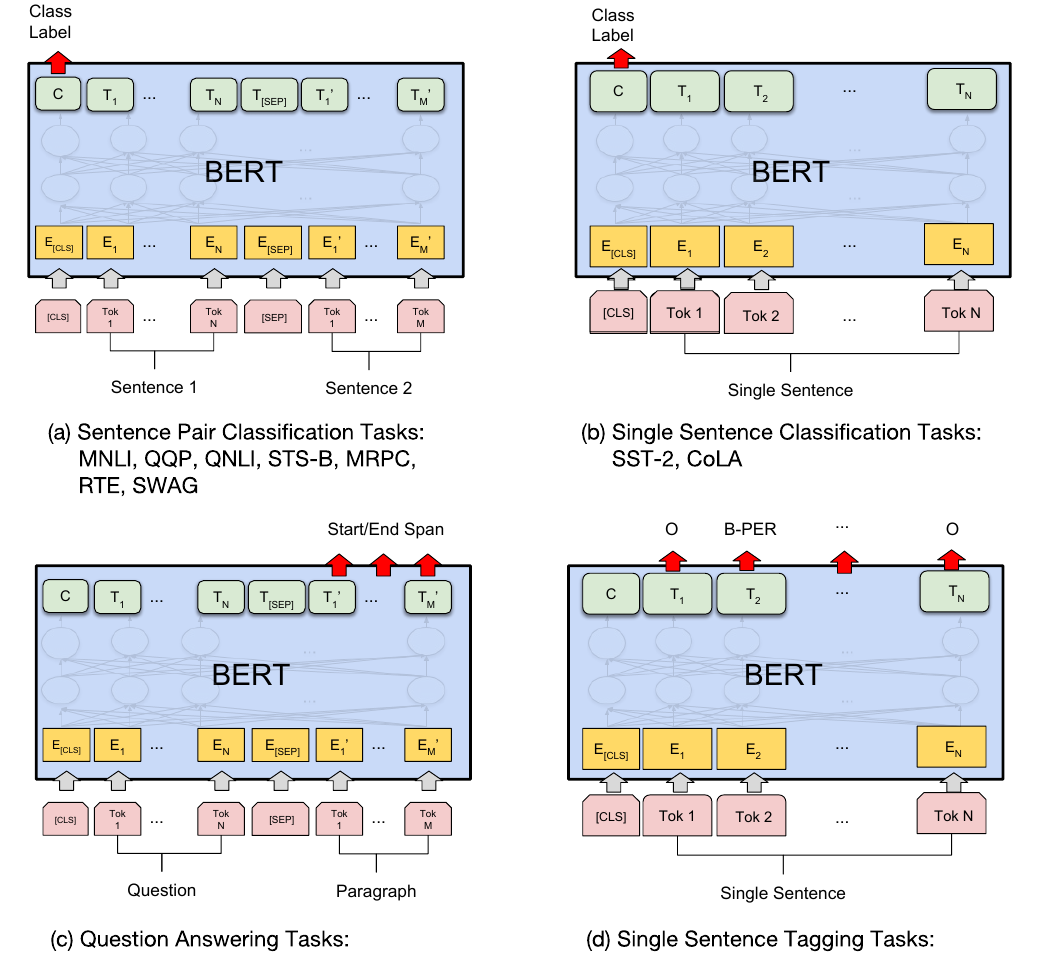
两种不同类型的任务所需要的向量,详情见特定任务的BERT
sentence-level:一般只拿CLS位置的向量,过线性层再softmax即可得到分类结果 token-level:SQuAD或NER,取对应位置的向量,过线性层再softmax得到相应的结果
如何构建词向量?
对于一个单词而言,通过整合它在 Bert 不同层输出的向量,一共提供了 6 中构建词向量方法。通过对 NER 任务的实验,发现效果最好的是拼接最后四层的输出向量 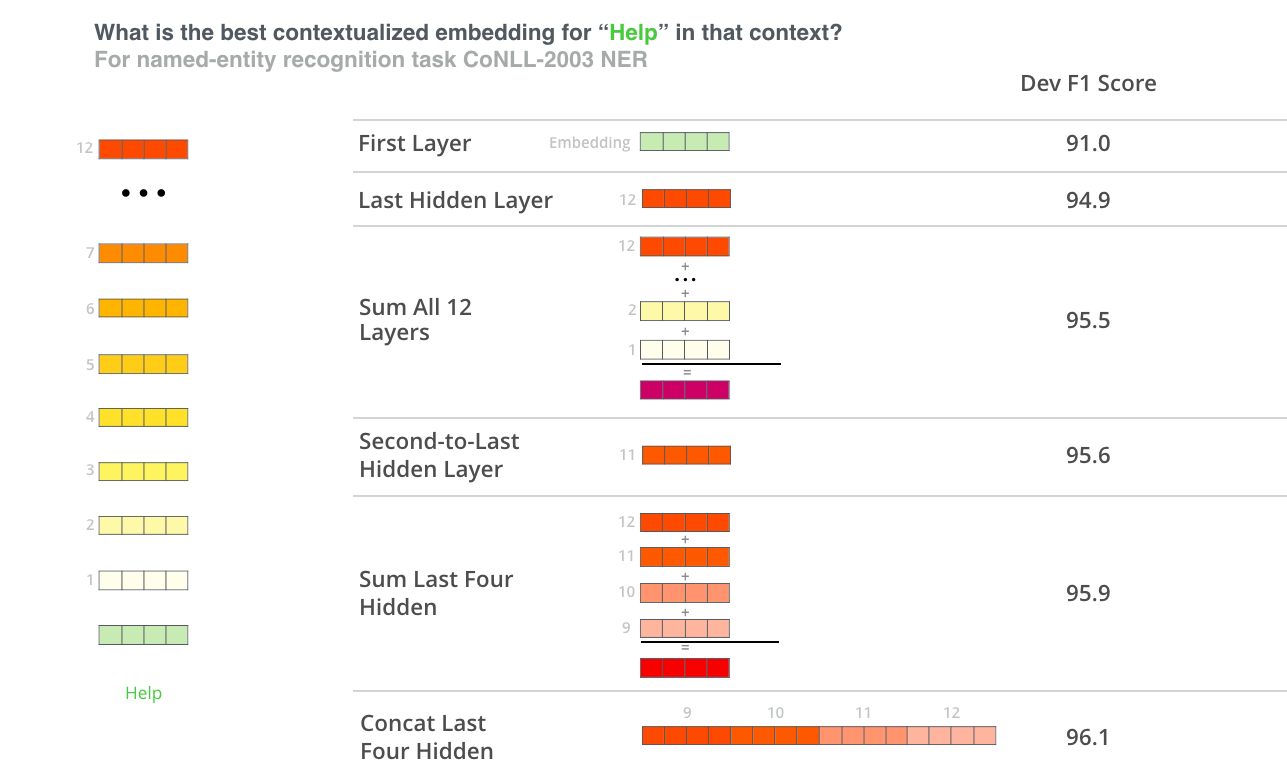
跟其他模型对比
参考 (References)
- Bert:: Pre-training of Deep Bidirectional Transformers for Language Understanding
- https://plmsmile.github.io/2018/12/15/52-bert/
- https://wmathor.com/index.php/archives/1456/
- https://zhuanlan.zhihu.com/p/48612853
- https://zhuanlan.zhihu.com/p/46652512
- http://fancyerii.github.io/2019/03/09/bert-theory/