What's the Problem?
This paper is targeted to measure the domain relevance of terms.
Why they do this Work?
The author mentioned 3 challenges:
- How to measure the domain relevance of a long-tail terms (not frequently used, and lake of descirptive information).
- How to measure domain relevance of a term without using domain-specific corpus.
- How to reduce human efforts.
How they deal with the problem & solve the challenges?
The overview of the framework is described in following picture. They assume that if a term is highly relevant to a target domain, this term should also be highly relevant to some other terms with high domain relevance. 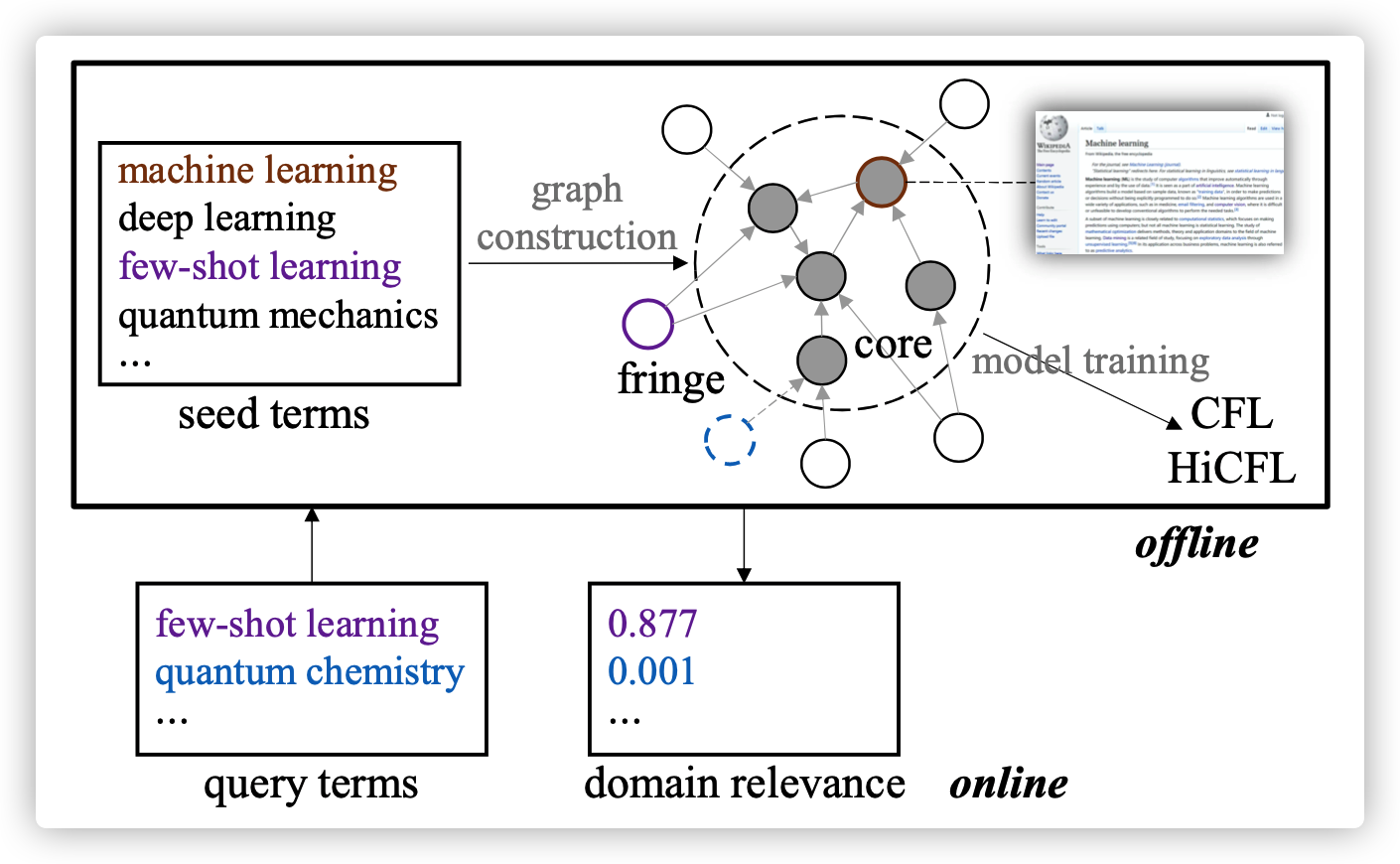
1. Core-Anchored Semantic Graph (for challenge 1)
First, the seed terms are provided by a term/phrase extraction method.
the seed terms can be divided into core terms (which is descibed by a Wikipedia article page) and fringe terms (which can not retrieve any description page from Wikipedia)
For each query term (a seed term), search it form Wikipedia search engine by extract match. Link those core terms to the query term by checking the top 2k (k=5) returned Wiki pages (build up links with top k core terms). If the number of returned pages is no more k, than use relevance search to get return pages and build up links.
By searching each seed term from Wikipage search engine and building up links between them, we construct a term graph.
The idea is using the term relevance between core terms and query term, thereofre, helping identifying the domain relevance of a query term.
2. Hierarchical Core-Fringe Learning (for challenge 2)
- For meansuring the doamin relevance with a broad domain, they proposed a Core-Fringe Domain Relevance Learniing (CFL) framework.
The graph convolution operation (GCNConv) at \(l\)th layer is formulated as:
\(h_i^{(l+1)}=\phi(\sum_{j\in \mathcal{N}_I\cup \{i\}}\frac{1}{c_{ij}}W_c^{(l)}b_c^{(l)}+b_c^{(l)})\)
The loss function is defined as:
\(\mathcal{L}=-\sum_{i\in \mathcal{V}_{core}}(y_ilog(z_i)+(1-y_i)log(1-z_i))\)
where \(\mathcal{V}_{core}\) is the nodes of core terms, \(y_i\) is the label of node \(i\) regarding the target domain (can be obtained in next step 3). The domain relevance is obtained from \(z\).
- For a narrow domain, they proposed a Hierarchical CFL (HiCFL) framework.
Get the last GCNConv layer \(h_i^{(l_c)}\), where $l_c $ is the total layer of GCN.
Obtain the hierarchical global hidden state \(a_p\) by
\(a_p^{(l+1)}=\phi(W_p^{(l)}[a_p^{(i)};h^{(l_c)}]+b_p^{(l)})\), and \(a_p^{(0)}=\phi(W_p^{(0)}h^{l_c}+b_{p}^{(0)})\), where \(l_p\) is the total number of hierarchical level.
The global information is produced by \(z_p = \sigma(W_p^{(l_p)}a_p^{(l_p)}+b_p^{(l)})\)
Obtain local hidden state \(a_q^{(l)}\) for each level of hierarchy
\(a_q^{(l)}=\phi(W_t^{(l)}a_p^{(l)}+b_t^{(l)})\), note this formula has related to global hidden state.
The local information of \(l\)th level of hierarchy is \(z_q^{(l)}=\sigma(W_q^{(l)}a_q^{(l)}+b_q^{(l)})\)
The loss function is defined as \(\mathcal{L}_h=\epsilon(z_p,y^{(l_p)})+\sum_{l=1}^{l_p}\epsilon(z_q^{(l)}, y^{(l)})\), where the \(\epsilon(z,y) = -\sum_{i\in \mathcal{V_{core}}}(y_ilog(z_i)+(1-y_i)log(1-z_i))\)
The final domain relevance can be calculated by \(s = \alpha \cdot z_p+(1-\alpha\cdot(z_q^{(1)}\circ z_q^{(2)},..,z_q^{(l_p)})\)
3. Automatic Annotation and Hierarchical Positive-Unlabeled Leraning (for challenge 3)
If the target domain is general enough to get its sub fields (sub-categories) form wikipedia or other existing domain taxonomies. Then get those sub-categories as the gold subcategories \(GSC\) of this domain. Then label those core terms whose Wiki page has a category in \(GSC\) with positive label. Otherwise, label it as non-domain terms.
If the target domain is a low-level category in a domain taxonomy. Then let user offer some terms of this domain and label them as positive. And label other terms which not belong to the parent of this domain to negatives. For example, For a hierarchy CS \(\rightarrow\) AI \(\rightarrow\) ML \(\rightarrow\) DL. The user can offer some terms to be positives. Then other terms in CS but non-ML terms to be automatically labeled as negatives.
Why this method works better & Any evidence?
Any shortcoming?
- The representation for each node may not elaborate enough, we may provide some embeddings learning form the Wiki page so that representing nodes with more semantic information.
Further Readings
About term extraction
- Bag of what? simple noun phrase extraction for text analysis
- Automated phrase mining from massive text corpora
References
- https://arxiv.org/pdf/2105.13255.pdf
- https://github.com/jeffhj/domain-relevance