What's the Problem?
Why they do this Work?
Most literature works are designed for a particular domain or document type. This work can be fitted in different areas and document types.
Most solutions generate the ontology that can only be manipulated by their tools. This work can generate standardized ontology with OWL languages which can be supported by many tools.
(3)Solutions from literature require intervention of specialists or algorithms that take much time. This work can offer a simple and relatively quick method to do so.
How they deal with the problem & solve the challenges?
Suppose there exist \(d\) documents and \(w\) unique words. This work do latent semantic analysis on documents by using a Singular Value Decomposition (SVD). This method decomposes the term-document matrix \(A\) (\(w\times d\)) into \(U\), \(\Sigma\) (\(w\times w\)), and \(V^T\) (\(n\times d\)) matrix, where \(V\) provides the relation between concepts and documents, and \(U\) offers the relation between terms and concepts. \(\Sigma\) is a diagonal matrix where the element in the diagonal specifys the importance of the eigenvectors in \(U\). Suppose that \(B=A^TA\), \(C=AA^T\), \(U\) is the matrix of eigenvectors of \(B\)(\(w\times w\)), \(V\) is the matrix of eigenvectors of \(C\)(\(d\times d\)). 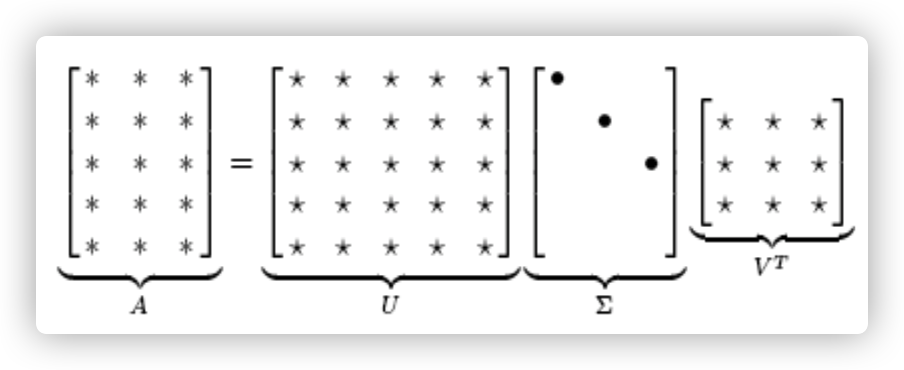
\(U\) – the left Eigen vector (orthogonal) matrix, the vectors extract “Strength of Two Different Words Occurring in one Document” (may or may-not be co-occurrence).
\(V\) – the right Eigen vector (orthogonal) matrix, the vectors extract “Document-to-Document similarity”.
\(\Sigma\) – the Eigen Values (diagonal) matrix, explains variance ratio
Why this method works better & Any evidence?
Any shortcoming?
Backgrounds
1 | G. R. Maddi, C. S. Velvadapu, S. Strivastava e J. G. d. Lamadrid, “Ontology Extraction from Text Documents by Singular Value Decomposition,” em ADMI 2001, 2001 |
presents a work using SVD to obtain concepts and terms and represent the obtained ontology by a bipartite graph.
1 | B. Fortuna, D. Mladenic e M. Grobelniz, “Semi-automatic Construction of Topic Ontology,” em Lecture Notes in Computer Science, vol. 4289, Springer, 2005, pp. 121-131 |
extract concepts as term sets.
1 | J. Yeh e N. Yang, “Ontology Construction on Latent Topic Extraction in a Digital Library,” em International Conference on Asian Digital Libraries 2008, 2008 |
construct ontology from a historial digital library, where the concepts is generated by using latent semantics, and hierarchies among concepts are obtained by using clustering method.
1 | Y. Ding e S. Foo, “Ontology Research and Development Part 1 – A Review of Ontology Generation,” Journal of Information Science, vol. 28, pp. 123-136, 2002. |
present a study of concepts generation focused on clustering and latent semantic.
1 | L. Gillam e K. Ahmad, “Automatic Ontology Extraction from Unstructured Texts,” em the Move to Meaningful Internet Systems 2005: CoopIS, DOA, and ODBASE, 2005. |
propose the obtainment of concepts using statistical methods