Gated Reccurent Unit (GRU) is a simplified from the architecture of LSTM. It has fewer parameters than LSTM, therefore, it takes less compution resource and run faster than LSTM.
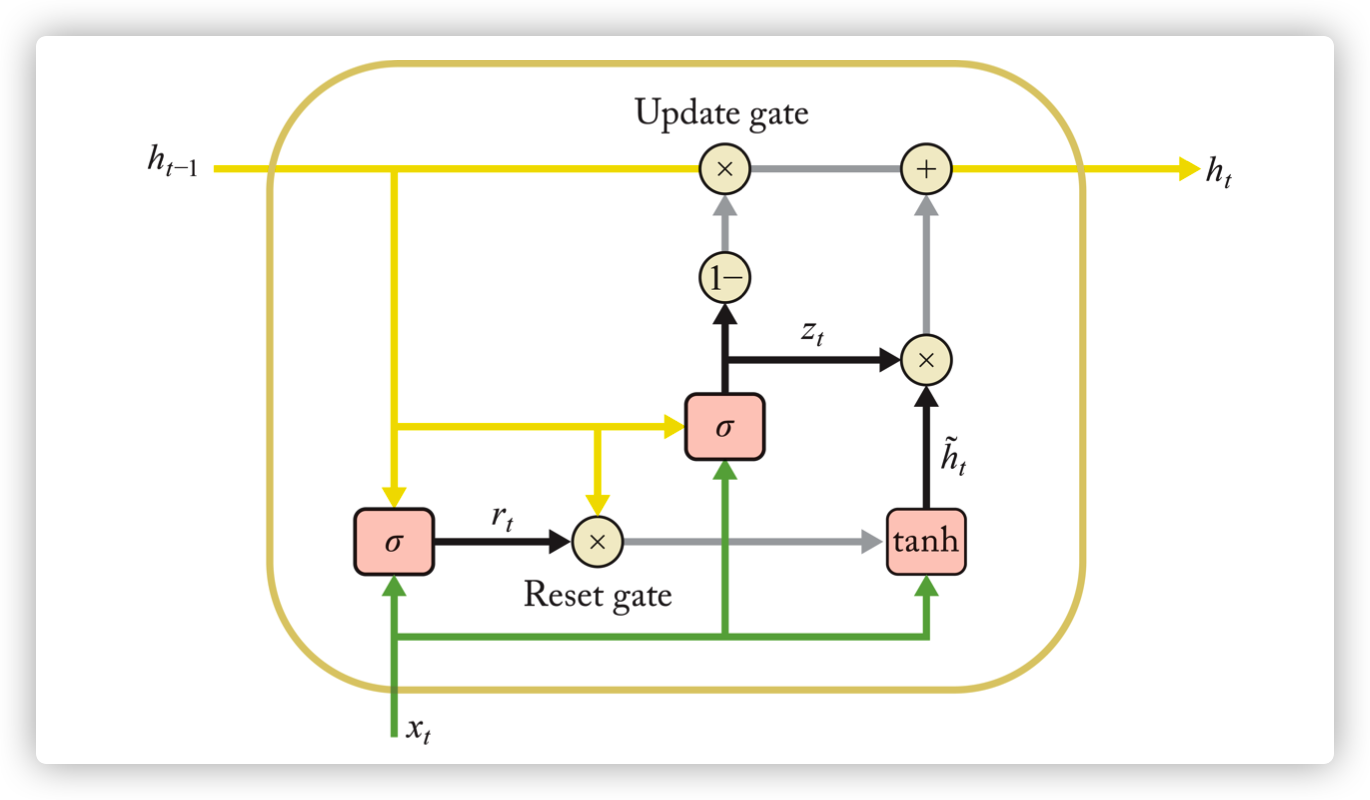
To be detailed, GRU combines forget and input (update) gates into a single update gate, and merges cell and hidden states. The comparison between LSTM (left hand side) and GRU (right hand side) is described in following picture.
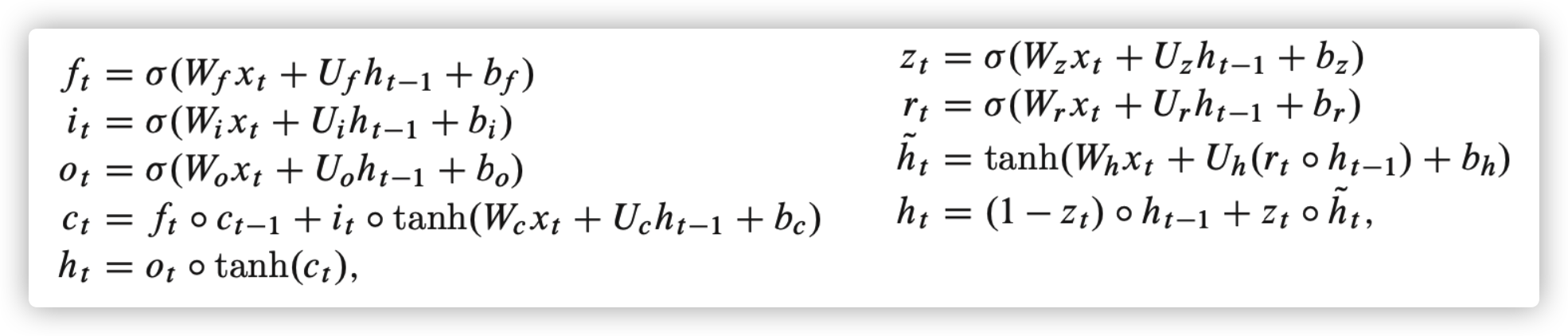
where \(z_t\) and \(r_t\) are repective activation vecotrs for the update and reset gates.
References
- Chung, Junyoung, et al. "Empirical evaluation of gated recurrent neural networks on sequence modeling." arXiv preprint arXiv:1412.3555 (2014).
- Pilehvar, Mohammad Taher, and Jose Camacho-Collados. "Embeddings in natural language processing: Theory and advances in vector representations of meaning." Synthesis Lectures on Human Language Technologies 13.4 (2020): 1-175.