torch.reshape()
y = x.reshape([batchsize, -1, sentsize, wordsize]) 意思是把 x 的形状改为 (batch, -1, sentsize, wordsize),其中 -1 这个维度的大小根据其他维计算的,也就是 total_size/batch/sentsize/wordsize
torch.view()
- 该方法与 reshape 功能相同,都是重组张量。但是它只能用于改变连续(contiguous)张量,否则要调用 contiguous() 方法,reshape() 不受影响
- view() 返回的张量与原张量共享基础数据(不是共享内存地址),而 reshape() 如果可以返回 view 就返回,否则返回 copy
指导: 如果需要原张量的拷贝(copy),就使用.clone()方法; 而如果需要原张量的视图(view),就使用.view()方法; 如果想要原张量的视图(view),但是原张量不连续(contiguous),不过原张量拥有兼容的步长(strides),此时可以考虑使用.reshape()函数。
1 | a = torch.randint(0, 10, (3, 4)) |
torch.resize()
1 | a = torch.arange(24).view(4, 6) |
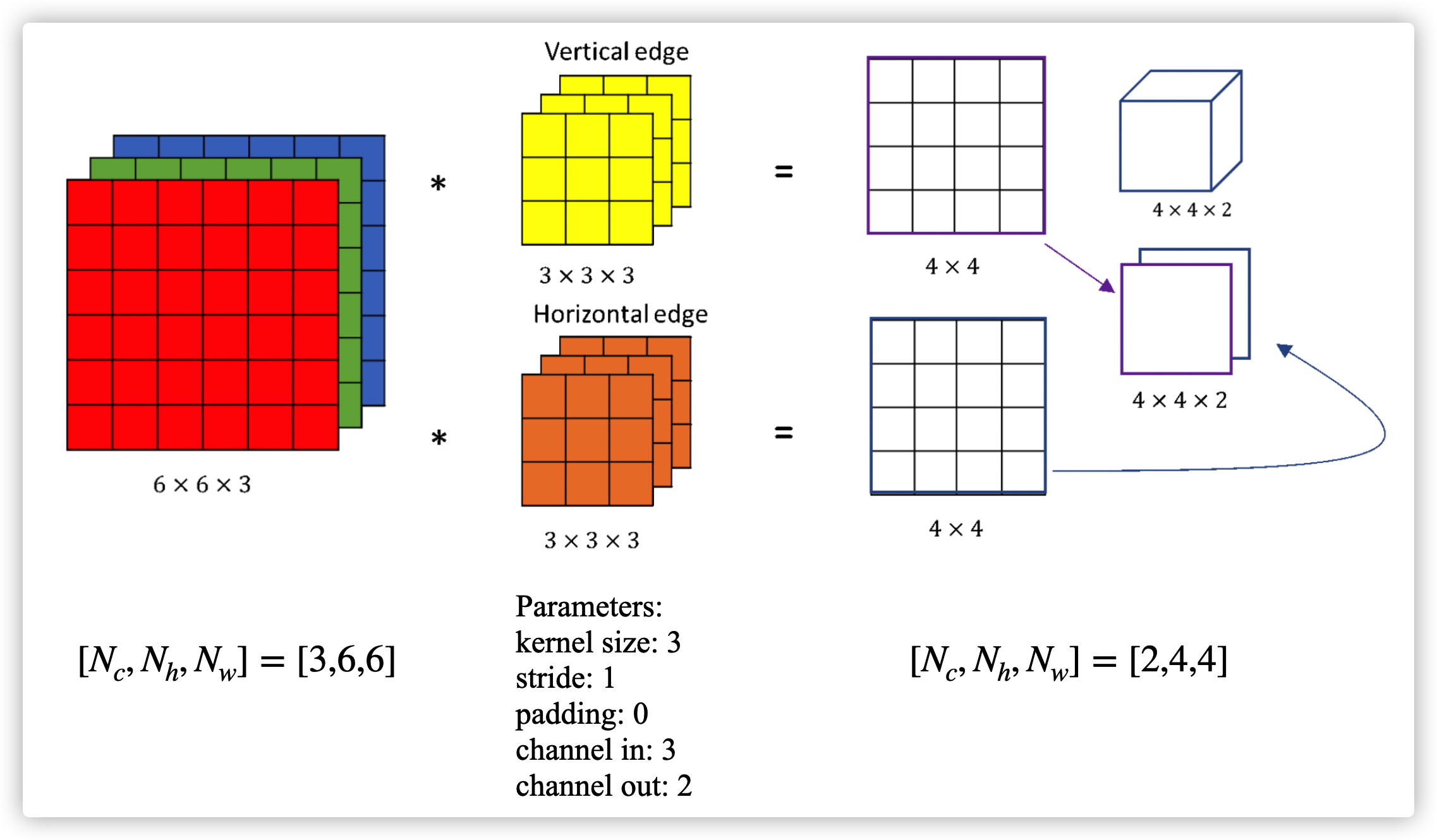
torch.nn.Conv2d()

torch.nn.Conv2d(1, 10, kernel_size=3,stride=2,bias=False)
- 1 是指输入的 Channel (channel in),即图像层数(灰度图 1 层,RGB图 3 层)
- 10 是指输出的 Channel (channel out),也可以指这一层中卷积核的个数
- 3 是指卷积核的边长,参数大小为 3*3
- 2 是指步长,即卷积核平移时要跨多少个位置
- 卷积后每个 channel 的边长 = (原始边长 - (kernel_size-1) + 2padding) / stride. e.g. (6- (3-1) + 20) / 1 = 4
torch.nn.LSTM()
- input_size: 输入的维度
- hidden_size: 隐藏层向量维度
- num_layers: LSTM 堆叠的层数。注意双向的 Bi-LSTM 也只能算一层
- bias: 是否加入偏置
- batch_first: 若为 True,输入格式按照 [batch_size, seq_len, input_size],原始格式为 [seq_len, batch_size, input_size]
- dropout: 对网络参数 dropout 的比例
- bidirectional: 是否双向传播
输入 - input (seq_len, batch, input_size) - h_0 (num_layers * num_directions, batch, hidden_size) - c_0 (num_layers * num_directions, batch, hidden_size)
输出 - output (seq_len, batch, num_directions * hidden_size) - h_n (num_layers * num_directions, batch, hidden_size) - c_n (num_layers * num_directions, batch, hidden_size)
举例子:假设词向量维度为 100,句子包含 24 个词,一次训练 10 个句子。那么 batch_size=10, seq_len=24, input_size=100。隐藏层的输出的维度为 hidden_size,它主要用于设置隐藏层向量表示和参数 W,b 的维度。
如果 hidden_size=16,则 \(W_{i}\) 的 shape 为 16×100,\(x_t\) 的 shape 为 100×1,\(W_{g}\) 的 shape 为 16×16, \(h_{t-1}\) 的 shape 为 16×1。
输入门:
\(i_t=\sigma(W_{ii}x_t + b_{ii} + W_{hi}h_{t_1}+b_{hi})\)
遗忘门:
\(f_t=\sigma(W_{if}x_t+b_{if}+W_{hf}h_{t-1}+b_{hf})\)
\(g_t=tanh(W_{ig}x_t+b_{ig}+W_{hg}h_{t-1}+b_{hg})\)
输出门:
\(o_t=\sigma(W_{io}x_t+b_{io}+W_{ho}h_{t-1}+b_{ho})\)
两种记忆:
长期记忆:\(c_t=f_t*c_{t-1}+i_t*g_t\)
短期记忆:\(h_t=o_t*tanh(c_t)\)
tensor.detach() vs tensor.detach_()
这两个方法都会分离模型中的某些参数(通过 self.grad_fn=None)。detach_() 除了冻结节点,还会更改变量的依赖关系有向无环图。这种机制可以实现模型的微调,比如一些语言模型在某个具体分类问题上的微调,其实只需要重新训练分类器就好了,不需要再去学习向量表达 参考。
detach() 从当前图分离的新变量,该变量永远不会用梯度。返回了一个复制了的变量与原变量指向同一个 tensor.
1 | def detach(self): |
detach_() 直接将变量从创建它的图中分离出来,把它作为叶子节点
1 | def detach_(self): |
比如存在这样一个变量依赖链 \(x\rightarrow y \rightarrow z\),然后执行 y._detach(),此时整个变量的依赖关系也变化了 \(x, y\rightarrow z\)。如果是执行了 y.detach() 可以达到相同效果,但是保留了原有的图结构。
假设有两个 layer: \(y = A(x), z=B(y)\),我们想用 z.backward() 为 B 的参数梯度,但是不想求 A 的参数梯度。可以这样实现: 1
2
3
4
5
6
7
8
9
10# 第一种方法 x -> y -> z
y = A(x)
z = B(y.detach())
z.backward()
# 第二种方法 x, y -> z
y = A(x)
y.detach_()
z = B(y)
z.backward()y.backward(),但是第二种方法不能 y.backward(),因为 x 与 y 已经在原图中断开了。